

Building an AI Ops Stack for Small Teams: Evaluation, Routing, and Release Discipline
Small teams do not need a giant platform to run AI well. They need a disciplined operating stack: clear tasks, test sets, model routing, human review, observability, and a release rhythm that treats prompts and workflows like product surfaces.
Maintained Editorial Article
This article focuses on comparison logic, evaluation criteria, and pre-trial questions. When it references third-party products, pricing, permissions, or service details, readers should still verify those details with the original source.
Small teams are often told two contradictory stories about AI. The first story says they should move fast, wire a powerful model into everything, and trust the raw capability curve to do the heavy lifting. The second story says they need a full enterprise platform before they can do anything serious. Both stories are misleading. A small team does not need a giant procurement exercise, but it also cannot survive on improvised prompts and hopeful demos. What it needs is an AI ops stack that is narrow, opinionated, and disciplined.
By AI ops stack, I mean the minimum system that lets a team ship model-powered work repeatedly without losing control. That system usually includes five things: task definitions, evaluation sets, routing rules, human review, and operational telemetry. None of these pieces is glamorous. They do not make for flashy launch videos. But once they exist, a two-person or six-person team can move with much more confidence than a larger organization that still treats every model interaction like an isolated experiment.
1. Start with workflow surfaces, not with a model wishlist
Teams frequently begin by debating models. Should they standardize on the strongest reasoning model, add a cheaper fallback, adopt a multimodal option, or host something locally? Those questions matter, but they are not the first questions. The first question is which workflow surfaces deserve operational attention. A workflow surface is a recurring task where output quality, speed, and consistency affect the team materially: support replies, research digests, article drafts, QA summaries, CRM enrichment, bug triage, or release note generation.
Once those surfaces are explicit, model choices become easier because every surface carries different requirements. A customer-facing reply assistant may demand tight tone control and low latency. A weekly market brief may tolerate more latency but require stronger synthesis and citations. A code review summarizer may need access to diffs and internal conventions. Small teams gain leverage when they define these surfaces first and only then choose how models, retrieval, templates, and review should support them.
- Define the recurring task in one sentence.
- Write down the input sources and the expected output shape.
- Name the human owner of the final result.
- Record what failure actually looks like for that task.
- Set a default path for escalation or re-run.

2. Evaluation is the first serious product requirement
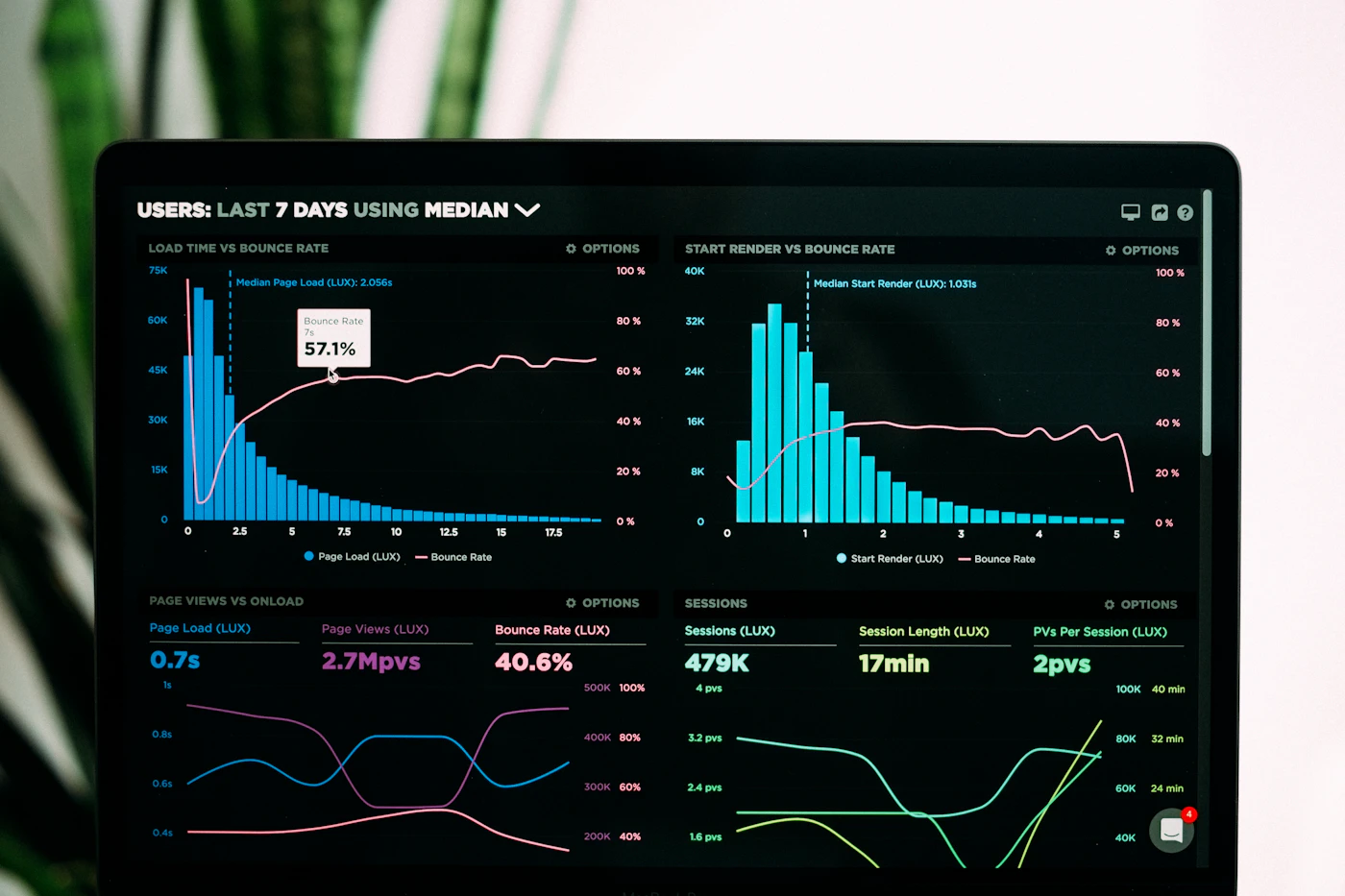
The fastest way for a small team to lose trust in AI is to skip evaluation until after launch. In early experiments, teams often rely on intuition: this draft looks better, that answer feels weaker, the model seems more concise. The problem is that intuition cannot survive change. As soon as the prompt evolves, the model version shifts, a retrieval source is updated, or a new routing rule is introduced, subjective memory stops being useful. You need a fixed set of examples that tell you whether the workflow has improved, regressed, or simply changed character.
A good evaluation set for a small team does not need to be enormous. Twenty carefully chosen examples can be more valuable than two hundred random ones. What matters is coverage. Include typical inputs, ugly inputs, ambiguous inputs, incomplete inputs, and historical failures. Then define how the workflow will be judged. Not just “quality,” but specific criteria: factual accuracy, required structure, adherence to style, refusal behavior, citation completeness, turnaround time, and average cost per run. Once those criteria exist, changes stop feeling mystical. They become measurable product decisions.
3. Model routing is how small teams buy flexibility without chaos
A single-model strategy is attractive because it feels simple. In reality, it often becomes expensive, brittle, or both. Small teams do better with a modest routing layer that maps workflows to the right model class. The key is not to over-engineer. You do not need a giant orchestration fabric. You need a small, explicit matrix: which tasks require strong reasoning, which tasks can use a fast economical model, which tasks need multimodal input, which tasks must stay within a private environment, and which tasks demand tool use or browsing.
Routing rules should also encode policy, not just performance. For example, public-facing content may require a model that reliably follows formatting instructions and supports source grounding. Internal brainstorming may use a cheaper model with looser constraints. Sensitive internal analysis may be restricted to approved environments. When teams make these decisions explicit, they stop wasting energy on repeated tactical debates. More importantly, they can change models without destabilizing the whole workflow, because the operational contract lives above the model.

4. Human review is not a tax, it is part of the system design
There is a persistent temptation to treat human review as a temporary crutch. Teams say they will keep the reviewer “for now” and eventually remove that step once the model improves. That mindset usually leads to bad design. Review is not merely compensation for model weakness. It is where accountability lives. If an output affects customers, revenue, brand, compliance, code, or decision making, there should be a clear human checkpoint. The question is not whether review exists, but how well it is designed.
Effective review is lightweight and evidence-based. The reviewer should see the prompt version, the relevant inputs, key citations or references, and the reasons a route was chosen when that context matters. Review should also produce useful signals for improvement: why the reviewer changed the wording, what risk they spotted, which factual claim needed correction, and whether the failure came from context quality, prompt structure, routing, or the base model. Over time, those review traces become the most valuable source of optimization data in the stack.
5. Observability matters before scale, not after it
Small teams sometimes postpone observability because their volume is still low. That is backwards. At low volume, every failure matters more because each one shapes trust. The minimum observability layer should capture run counts, latency, model usage, estimated cost, re-run frequency, review outcomes, and common error signatures. If a workflow depends on retrieval or tool calls, log those too. You do not need a baroque dashboard, but you do need enough evidence to answer practical questions: what changed, why did costs spike, which tasks are unstable, and what keeps getting sent back by reviewers.
Without these signals, teams often confuse symptoms with causes. They assume a model is getting worse when the real problem is degraded input quality. They blame prompting when the actual issue is a broken retrieval source. They think routing is fine because the final outputs look acceptable, even though cost has doubled quietly over two weeks. Observability turns operational AI from anecdote into engineering. That shift is what allows a small team to stay fast without becoming reckless.
6. Ship AI changes with release discipline
Perhaps the most underrated advantage a small team has is that it can adopt release discipline quickly. Prompt changes, retrieval updates, model swaps, rubric edits, and route adjustments should be treated like product releases, not ad hoc edits. That means a changelog, a short justification, a documented owner, a quick evaluation pass, and a rollback path. This may sound formal for a small group, but it is precisely what keeps a small group from getting buried under invisible complexity.
When AI surfaces are operated with this level of discipline, teams discover something useful: the stack becomes composable. A reliable research workflow can feed a reliable drafting workflow. A reliable drafting workflow can feed a reliable QA or publishing workflow. That composability is where leverage compounds. The goal is not to have the fanciest AI stack in the room. The goal is to build one that keeps producing useful work, remains explainable under pressure, and gets better every time the team learns something real.

Enterprise AI
从提示词到系统能力:企业把多模型接入业务流程的落地手册
企业接入大模型最容易卡在两个极端之间:一端是只做聊天入口,另一端是一口气追求“全业务智能化”。真正可持续的方法,是围绕任务类型、成本、风险和治理能力建立多模型路由,再把提示词、知识、权限和评估一起产品化。

Support Automation
客服自动化工具上线前先筛这 5 项:接管机制、知识范围、异常处理、CRM 衔接、维护成本
客服自动化工具最容易在演示里显得顺滑,但真正决定能不能上线的,往往是接管机制、知识边界和异常处理能不能扛住真实工单。这篇文章给出一张适合团队上线前使用的检查清单。

Team Productivity
会议纪要 AI 工具别只看转写率:团队筛选会议助手时真正该查的 6 件事
会议助手类产品最容易因为“自动转写和摘要”看起来很顺而快速通过试用,但真正影响能否长期使用的,往往是权限、会后分发、纪要结构、责任边界和搜索复用方式。